Evil Re: An introduction to ReDoS vulnerabilities
Regular Expression Denial of Service (ReDoS) is one of those vulnerabilities that quietly lurks beneath the surface of everyday code; rarely looked for and capable of causing far more disruption than most developers or testers recognise. Over the last few assessments I’ve completed, I’ve uncovered multiple instances of ReDoS, each hidden inside complex regular expressions. Because these issues are easy to miss, difficult to detect without the right approach, and capable of triggering costly denial‑of‑service conditions in real‑world systems, I wanted to shed some light on how they work and why they matter.
How ReDoS Operates
Regular Expression Denial of Service (ReDoS) is a type of Denial of Service (DoS) vulnerability that takes advantage of the way applications process regular expressions (regex). Regular expressions are commonly used in software development for input validation, searching, and data extraction. However, certain patterns, particularly those involving nested quantifiers or ambiguous groupings, may be manipulated by attackers to significantly degrade application performance or even cause a crash.
ReDoS attacks typically leverage a phenomenon known as catastrophic backtracking. Many regex engines use matching algorithms that, when presented with complex or poorly designed patterns, are required to evaluate a large number of potential matching paths. If an attacker provides a carefully constructed input, the regex engine may be forced to examine every possible permutation, resulting in exponential increases in processing time. For example, a pattern such as:
(a+)+$
can be exploited using a long sequence of 'a' characters followed by a non-matching character. This can lead to thousands or even millions of backtracking operations.
So why are they often missed?
Well, it’s no surprise that these vulnerabilities are often overlooked because there’s a general consensus amongst penetration testers to take the stance: “We do not test for Denial of Service”. For the most part this is good news, because, as professionals attempting to support our clients, we do not want to cause unnecessary disruption. For live systems, or those that are processing real data and hosting functionality used on a day-to-day basis, a denial-of-service condition can cost a lot of money. It can also impact heavily on time and resources by forcing reverts, reboots, redeploys, etc.
It’s also relatively rare, on a day-to-day testing schedule, to get access to code. Code review is often reserved for super sensitive systems, or for a level of completeness that is required for very high functioning systems (such as high-freq trading, military, aerospace, OT, etc.) where stability is a hard requirement.
Because of this, regular expressions that are used within an application are obscured from the tester and in reality it’s difficult to conduct a set of tests that might lead to DoS. Furthermore, when the difference between a 1000 character string and a 16,000 character string is a high magnitude but still relatively small amount of time, it’s unsurprising that things like this can be missed.
Who cares?
Well, I do, for one. But ultimately, these accepted pentesting ‘norms’ create a situation where there’s an entire class of vulnerabilities available for exploitation in the wild - that can have significant real-world impact - going perpetually undiscovered and unfixed. Across my recent tests, it is evident that ReDoS vulnerabilities are prevalent, and could represent an untapped wonderland of pwnage for both testers and attackers alike.
A walk-through
Okay, so here I am, diligently reading through some code when I come across a series of checks and validations on input. The client has really gone above and beyond to ensure that all input is strongly validated to prevent injection-type attacks. Given the language that this system is written in, this is particularly wonderful to see. However, most of these have been implemented using regexps and so it occurrs to me that, with so many expressions in use, at least SOME of them are bound to be vulnerable.
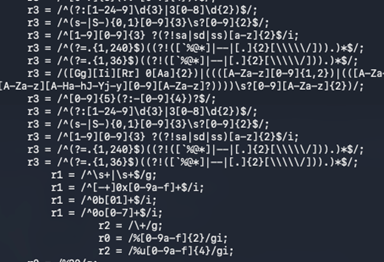
Well, there were over 400 regular expressions, and as you can see some of them were reasonably complex (on account of how strict the matching rules were for validation). Regardless, manually going through each regexp, matching against a suspected list of potentially exposing strings and then confirming each one individually was going to take an inordinate amount of time. We all know that time on engagements is always a restricting factor, and so I decided to create a tool that would allow me to navigate through them, constructing some test strings and evaluating the status of each regular expression. In effect, I wanted to automate the detection of ReDoS vulnerabilities.
Building the tool
It took maybe an hour to create a prototype, messing around and fiddling away with Python. I wanted something quick and dirty that would find at least one vulnerable regular expression – enough for me to create the write up and give a good estimation of which ones might cause problems down the line. I went through a number of iterations, because generically analysing Regular expressions isn’t trivial or straight forward and rather than just take ‘structural’ concepts, I also wanted to prove the point through testing and evaluation.
Firstly, I tried to apply some general principals for identifying RegExps.
Nested quantifiers - multiple layers of repetition create multitudinous possible ways to split the string
Quantifier and optional/ambiguous subpattern
Overlapping / mutually ambiguous alternatives
Very broad repeated pattern(especially with ., [\s\S], etc.)
Optional separator inside repetition
Long chain of optional/quantified groups
No/few anchors + broad repetition
These principals then applied a weight to the regexp and output a number that represented the risk level. The process was rudimentary and the weights could perhaps be refined further, but ultimately it served its purpose for the engagements I was working on.
As a worked example for this, take ‘nested quantifiers’. The code would:
find_groups(pattern) walk the pattern, tracking ( and ) (ignoring character classes) and collect each group’s content.
_score_nested_quantifiers(pattern, groups) loops those groups and checks two conditions:
The group itself is quantified (e.g., (...) +, (...) *, {m,n}) via has_quantifier_at(pattern, end + 1).
The inside of the group already has any quantifier (+, *, ?, or {m,n}) using contains_quantifier(content).
If both are true, it flags “nested quantifiers” because you have repetition inside a group that is itself repeated (classic (a+)+, (\w+)*, etc.).

I won’t go through every check, but I will elaborate on the timing principal. ReDoS attacks by their nature create exponential increases in time required for processing strings. Therefore, a timing check could be performed to determine the exponent with which processing increases, this was done as a second order check – that would subsequently add another weight to the overall score. This was calculated by the increase in time required between iterations.
It wasn’t flawless, it wasn’t even refined, but it seemed to work alright, so far.
I conducted some testing for false positive and negative findings, and the tool did produce a number of them. The script wasn’t perfect (it needed more refactoring, refinement and development) but for the most part it did its job, which was to speed up the processing of many regular expressions. It was certainly a win for an hour’s work. It also proved that some of the regular expressions used in the test I was conducting were indeed vulnerable to ReDos. Finally, it allowed me to flex some brain power addressing a problem that is non-trivial. Regular expressions, while having a strong language, can be wildly complex and layered in ways that make it hard to generically define them. It’s also not trivial to programmatically calculate strings that can test a specific regex for timing issues. So the problem was a fun one to solve, and resulted in a good, useful tool.
If you want to check out an online version of this tool (alas, I’m sorry to say that I did not invent the wheel) you can navigate to this wonderful page:
https://makenowjust-labs.github.io/recheck/playground/
RegExpression Difficulties
Writing code to analyse and programmatically test regular expressions can be surprisingly difficult because regex behaviour is often full of edge cases and subtle rules that vary between different engines and languages. Even small changes to a pattern can alter matching in non-obvious ways, especially when features like ‘greedy versus lazy’ quantifiers, backtracking, lookarounds and multiline modes come into play. On top of that, it’s rarely enough to test a regex against a few typical examples: you also need to consider unusual inputs, ambiguous matches, performance problems such as catastrophic backtracking, and how capturing groups behave across repeated matches. As a result, building reliable tooling to evaluate correctness, predict performance, and produce meaningful test coverage is a fiddly task, requiring careful handling of both syntax and real-world data.
Next Steps
As long as regular expressions remain a staple of input validation and data processing, they will continue to be fertile ground for ReDoS vulnerabilities, particularly when nested quantifiers or ambiguous groupings are involved. As testers, an awareness of this type of vulnerability is another weapon to add to our arsenal. I’ll certainly continue to refine the tool - tightening the logic, reducing false positives and negatives, and shaping it into something more robust that I can rely on during future assessments.